WordPress is one the most popular tools for publishing content on the web. Everything from e-commerce websites to blogs can be developed using WordPress. Additionally, the WordPress community has built up a huge offering of free themes and plugins to make it easy for newcomers to get content published on the web quickly and easily.
However, just posting content on the web isn’t enough for many; attracting people to your site is part science, part art — and many SEO WordPress plugins help you do just that. This is a listing of top-notch WordPress plugins for SEO to improve your WordPress site’s search engine rankings.
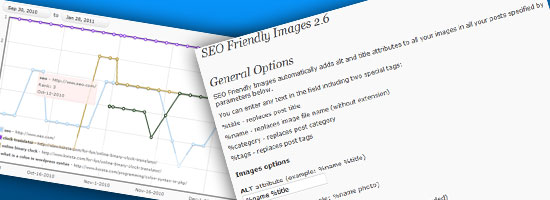
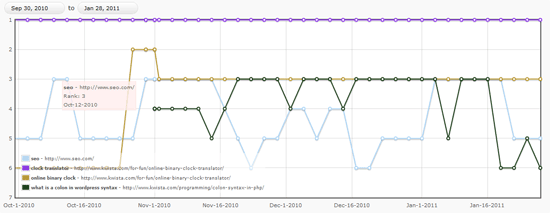
This WordPress SEO plugin allows you to track certain keywords in your site, and then issues you a report every 3 days (with all sorts of pretty graphs to boot). The plugin will also notify you via email whenever certain keywords experience major changes in search engine ranking.
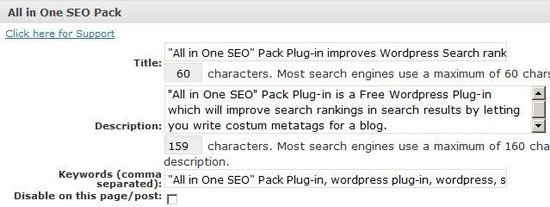
Any basic research on SEO plugins for WordPress will lead you to All in One SEO Pack. It is the most popular solution for your WordPress site’s search engine optimization. This plugin automatically optimizes your WordPress site for search engines by generating meta tags and helping you optimize web page titles. Advanced users are given the ability to customize post titles, descriptions, URL structures and tags for each post.
SEO Ultimate is one of the best SEO plugins for a WordPress site. It is a suite of tools for, well, ultimate SEO. It has a feature called Canonicalizer, which extends WordPress’s native canonical features to ensure that web spiders are pointed to the primary post in the case of web pages with the same content, but different URLs. It has a built-in robot.txt editor (one of the five web files that will enhance your site) that will allow you to easily set up this file for optimal search engine indexing. It works well with All in One SEO Pack, allowing you to import meta-data from it if you wanted to switch to SEO Ultimate.
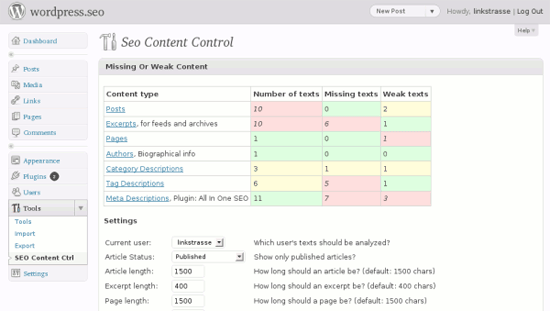
This nifty WordPress SEO plugin helps you identify weak content on your site. For example, many WordPress owners forget to include descriptions of their categories, which is a potential point of improvement for enhancing your search engine rankings. SEO Content Control helps you easily identify these potentially troublesome areas.
Optimizing images for search engines is often neglected; but when done right, you increase their semantic value, accessibility, and search engine indexability, especially for image searches. This WP SEO plugin automatically updates your images with alt and title attributes.
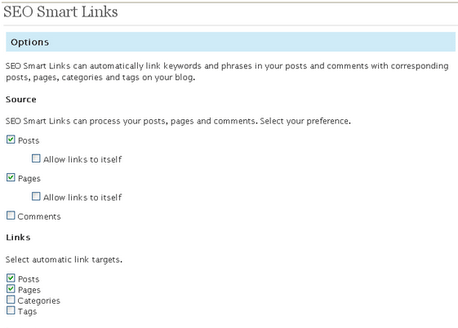
SEO Smart Links is a WordPress SEO plugin that automatically links keywords and phrases in your blog posts based on previous pages and posts. SEO Smart Links gives you the ability to set up your own unique keywords and sets of matching URLs. It also allows you to set nofollow attributes and open links in new browser windows or browser tabs. A very convenient way to save time, learn a bit about SEO best practices and interlink blog posts.
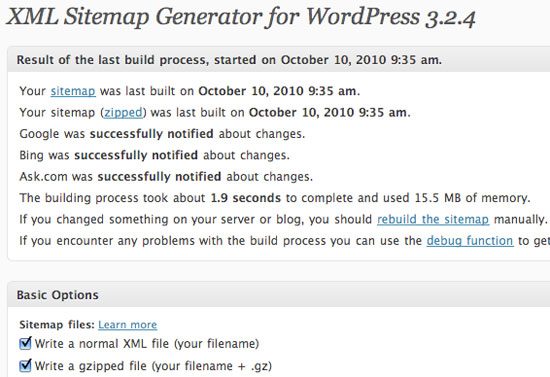
This SEO WordPress plugin is able to generate an XML sitemap that will assist search engine spiders in crawling and indexing your WordPress site. XML Sitemaps reveals the structure of your site’s content in a transparent way for search engines. Google XML Sitemaps also includes support for Bing, Yahoo!, Ask.com, and MSN, notifying them every time you create a post.
This WordPress plugin for SEO is loaded with plenty of features, including automatically generating meta tags, helping you optimize page and post titles for search engines, and aiding you in avoiding duplicate content (one of the ways to improve SEO of sites you design).
Conclusion
These SEO WordPress plugins will give your WP site a complete SEO overhaul. Installing them and getting to understand each plugin’s inner workings may take some time, but it is worth it to know how each plugin can benefit your site. When used correctly, your content will be more visible, potentially attracting additional traffic consisting of your target audience.
PHP Internals News: Episode 89: Partial Function Applications
London, UK
Thursday, June 17th 2021, 09:17 BST
In this episode of "PHP Internals News" I chat with Larry Garfield (Twitter) and Joe Watkins (Twitter, GitHub, Blog about the "Partial Function Applications" RFC.
Hi, I'm Derick. Welcome to PHP internals news, a podcast dedicated to explaining the latest developments in the PHP language. This is Episode 89. Today I'm talking with Larry Garfield and Joe Watkins about a partial function application RFC that they're proposing with Paul Crevela and Levi Morrison. Larry, would you please introduce yourself?
Larry Garfield 0:36
Hello World. I'm Larry Garfield or Crell on most social medias. I'm a staff engineer for Typo3 the CMS. And I've been getting more involved in internals these days, mostly as a general nudge and project manager.
Derick Rethans 0:52
And hello, Joe, would you please introduce yourself as well?
Joe Watkins 0:55
Hi, I'm Joe, or Krakjoe, I do various PHP stuff. That's all there is to say about that really.
Derick Rethans 1:02
I think you do quite a bit more than just a little bit. In any case, I think for this RFC, you, you wrote the implementation of it, whereas Larry, as he said, did some of the project management, I'm sure there's more to it than I've just paraphrased in a single sentence. But can one of you explain in one sentence, or if you must, maybe two or three, what partial function applications, or I hope for short, partials are?
Larry Garfield 1:27
Partial function application, in the broadest sense, is taking a function that has some number of parameters, and making a new function that pre fills some of those parameters. So if you have a function that takes four parameters, or four arguments, you can produce a new function that takes two arguments. And those other two you've already provided a value for in advance.
Derick Rethans 1:54
Okay, I feel we'll get into the details in a moment. But what are its main benefits of doing this? What would you use this for?
Larry Garfield 2:01
Oh, there's a couple of places that you can use partial application. It is what got me interested. It's very common in functional programming. But it's also really helpful when you want to, you have a function that like, let's say, string replace takes three arguments, two of which are instructions for what to replace, and one of which is the thing in which you want to replace. If you want to reuse that a bunch of times, you could build an object and pass in constructor values and save those and then call a function. Or you can just partially apply string replace with the things to search for, and the things to replace with and get back a function that takes one argument and will do that replacement on it. And you can then reuse that over and over again. There are a lot of cases like that, usually use in combination with functions that wants a callback. And that callback takes one argument. So array map or array filter are cases where very often you want to give it a function that takes one argument, you have a function that takes three arguments, you want to fill in those first ones first, and then pass the result that only takes one argument to array map or a filter, or whatever. So that's the one of the common use cases for it.
Truncated by Planet PHP, read more at the original (another 23522 bytes)
If you have obtained ebooks in the EPUB format, you are not restricted to reading it on your hardware ebook device
or mobile phone. This page lists many
free (and open source) EPUB
viewers that you can install on your computer to read them.
WordPress 5.8 Beta 2 is now available for testing!
This software is still in development, so it’s not recommended to run this version on a production site. Consider setting up a test site to play with it.
You can test the WordPress 5.8 Beta 2 in two ways:
Install/activate the WordPress Beta Tester plugin (select the Bleeding edge channel and the Beta/RC Only stream)
The current target for the final release is July 20, 2021. That’s just five weeks away, so your help is vital to ensure that the final release is as good as it can be.
Some Highlights
Since Beta 1, 26 bugs have been fixed. Here is a summary of some of the included changes:
Block Editor: Remove bundled block patterns and support the patterns directory. (#53246)
Block Editor: Add a type property to allow Core to identify the source of the editor styles. (#53175)
Build/Test Tools: Adds some tests for Quick Draft section in Dashboard. (#52905)
Build/Test Tools: Replaced @babel/polyfill with core-js/stable. (#52941)
Coding Standards: Further update the code for bulk menu items deletion to better follow WordPress coding standards. (#21603)
External Libraries: Update Underscore to version 1.13.1. (#45785)
General: A number of block editor, template mode and widget screen related fixes. (#51149)
Login and Registration: Improve the unknown username error message. (#52915)
Media: Restore AJAX response data shape in media library. (#50105)
Site Health: Display a list of file formats supported by the GD library. (#53022)
Testing for bugs is a vital part of polishing the release during the beta stage and a great way to contribute.
If you think you’ve found a bug, please post to the Alpha/Beta area in the support forums. We would love to hear from you! If you’re comfortable writing a reproducible bug report, file one on WordPress Trac. That’s also where you can find a list of known bugs.
If you’re reading this article, it’s likely that you spend a fair amount of time online. However, considering how much of an influence the Internet has in our daily lives, how many of us actually know the story of how it got its start? Most of our daily lives are saturated with social media, online shopping, and browsing for new information, but how did we get to this point?
Here’s a brief history of the Internet, including important dates, people, projects, sites, and other information that should give you at least a partial picture of what this thing we call the Internet really is, and where it came from.
While the complete history of the Internet could easily fill a few books, this article should familiarize you with key milestones and events related to the growth and evolution of the Internet between 1969 to 2009.
1969: Arpanet
Arpanet was the first real network to run on packet switching technology (new at the time). On October 29, 1969, computers at Stanford and UCLA connected for the first time. In effect, they were the first hosts on what would one day become the Internet.
The first message sent across the network was supposed to be “Login”, but reportedly, the link between the two colleges crashed on the letter “g”.
1969: Unix
Another major milestone during the 60’s was the inception of Unix: the operating system whose design heavily influenced that of Linux and FreeBSD (the operating systems most popular in today’s web servers/web hosting services).
1970: Arpanet network
An Arpanet network was established between Harvard, MIT, and BBN (the company that created the “interface message processor” computers used to connect to the network) in 1970.
1971: Email
Email was first developed in 1971 by Ray Tomlinson, who also made the decision to use the “@” symbol to separate the user name from the computer name (which later on became the domain name).
1971: Project Gutenberg and eBooks
One of the most impressive developments of 1971 was the start of Project Gutenberg. Project Gutenberg, for those unfamiliar with the site, is a global effort to make books and documents in the public domain available electronically–for free–in a variety of eBook and electronic formats.
It began when Michael Hart gained access to a large block of computing time and came to the realization that the future of computers wasn’t in computing itself, but in the storage, retrieval and searching of information that, at the time, was only contained in libraries. He manually typed (no OCR at the time) the “Declaration of Independence” and launched Project Gutenberg to make information contained in books widely available in electronic form. In effect, this was the birth of the eBook.
1972: CYCLADES
France began its own Arpanet-like project in 1972, called CYCLADES. While Cyclades was eventually shut down, it did pioneer a key idea: the host computer should be responsible for data transmission rather than the network itself.
1973: The first trans-Atlantic connection and the popularity of emailing
Arpanet made its first trans-Atlantic connection in 1973, with the University College of London. During the same year, email accounted for 75% of all Arpanet network activity.
1974: The beginning of TCP/IP
1974 was a breakthrough year. A proposal was published to link Arpa-like networks together into a so-called “inter-network”, which would have no central control and would work around a transmission control protocol (which eventually became TCP/IP).
1975: The email client
With the popularity of emailing, the first modern email program was developed by John Vittal, a programmer at the University of Southern California in 1975. The biggest technological advance this program (called MSG) made was the addition of “Reply” and “Forward” functionality.
1977: The PC modem
1977 was a big year for the development of the Internet as we know it today. It’s the year the first PC modem, developed by Dennis Hayes and Dale Heatherington, was introduced and initially sold to computer hobbyists.
1978: The Bulletin Board System (BBS)
The first bulletin board system (BBS) was developed during a blizzard in Chicago in 1978.
1978: Spam is born
1978 is also the year that brought the first unsolicited commercial email message (later known as spam), sent out to 600 California Arpanet users by Gary Thuerk.
1979: MUD – The earliest form of multiplayer games
The precursor to World of Warcraft and Second Life was developed in 1979, and was called MUD (short for MultiUser Dungeon). MUDs were entirely text-based virtual worlds, combining elements of role-playing games, interactive, fiction, and online chat.
1979: Usenet
1979 also ushered into the scene: Usenet, created by two graduate students. Usenet was an internet-based discussion system, allowing people from around the globe to converse about the same topics by posting public messages categorized by newsgroups.
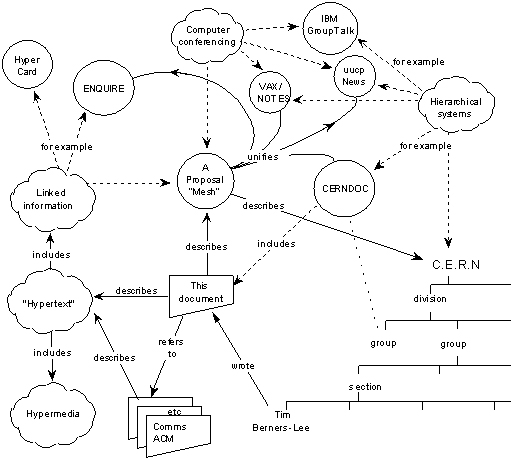
1980: ENQUIRE software
The European Organization for Nuclear Research (better known as CERN) launched ENQUIRE (written by Tim Berners-Lee), a hypertext program that allowed scientists at the particle physics lab to keep track of people, software, and projects using hypertext (hyperlinks).
1982: The first emoticon
While many people credit Kevin MacKenzie with the invention of the emoticon in 1979, it was Scott Fahlman in 1982 who proposed using after a joke, rather than the original -) proposed by MacKenzie. The modern emoticon was born.
1983: Arpanet computers switch over to TCP/IP
January 1, 1983 was the deadline for Arpanet computers to switch over to the TCP/IP protocols developed by Vinton Cerf. A few hundred computers were affected by the switch. The name server was also developed in ’83.
1984: Domain Name System (DNS)
The domain name system was created in 1984 along with the first Domain Name Servers (DNS). The domain name system was important in that it made addresses on the Internet more human-friendly compared to its numerical IP address counterparts. DNS servers allowed Internet users to type in an easy-to-remember domain name and then converted it to the IP address automatically.
1985: Virtual communities
1985 brought the development of The WELL (short for Whole Earth ‘Lectronic Link), one of the oldest virtual communities still in operation. It was developed by Stewart Brand and Larry Brilliant in February of ’85. It started out as a community of the readers and writers of the Whole Earth Review and was an open but “remarkably literate and uninhibited intellectual gathering”. Wired Magazine once called The Well “The most influential online community in the world.”
1986: Protocol wars
The so-called Protocol wars began in 1986. European countries at that time were pursuing the Open Systems Interconnection (OSI), while the United States was using the Internet/Arpanet protocol, which eventually won out.
1987: The Internet grows
By 1987, there were nearly 30,000 hosts on the Internet. The original Arpanet protocol had been limited to 1,000 hosts, but the adoption of the TCP/IP standard made larger numbers of hosts possible.
1988: IRC – Internet Relay Chat
Also in 1988, Internet Relay Chat (IRC) was first deployed, paving the way for real-time chat and the instant messaging programs we use today.
1988: First major malicious internet-based attack
One of the first major Internet worms was released in 1988. Referred to as “The Morris Worm”, it was written by Robert Tappan Morris and caused major interruptions across large parts of the Internet.
1989: AOL is launched
When Apple pulled out of the AppleLink program in 1989, the project was renamed and America Online was born. AOL, still in existence today, later on made the Internet popular amongst the average internet users.
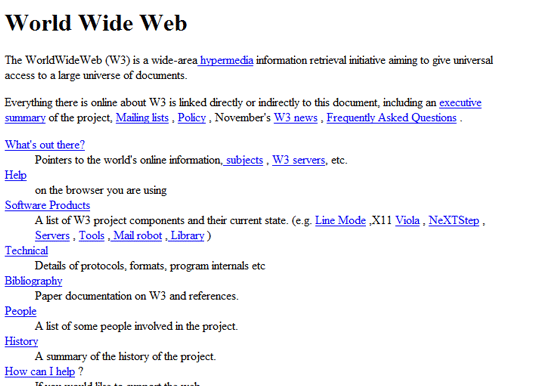
1989: The proposal for the World Wide Web
1989 also brought about the proposal for the World Wide Web, written by Tim Berners-Lee. It was originally published in the March issue of MacWorld, and then redistributed in May 1990. It was written to persuade CERN that a global hypertext system was in CERN’s best interest. It was originally called “Mesh”; the term “World Wide Web” was coined while Berners-Lee was writing the code in 1990.
1990: First commercial dial-up ISP
1990 also brought about the first commercial dial-up Internet provider, The World. The same year, Arpanet ceased to exist.
1990: World Wide Web protocols finished
The code for the World Wide Web was written by Tim Berners-Lee, based on his proposal from the year before, along with the standards for HTML, HTTP, and URLs.
1991: First web page created
1991 brought some major innovations to the world of the Internet. The first web page was created and, much like the first email explained what email was, its purpose was to explain what the World Wide Web was.
1991: First content-based search protocol
Also in the same year, the first search protocol that examined file contents instead of just file names was launched, called Gopher.
1991: MP3 becomes a standard
Also, the MP3 file format was accepted as a standard in 1991. MP3 files, being highly compressed, later become a popular file format to share songs and entire albums via the internet.
1991: The first webcam
One of the more interesting developments of this era, though, was the first webcam. It was deployed at a Cambridge University computer lab, and its sole purpose was to monitor a particular coffee maker so that lab users could avoid wasted trips to an empty coffee pot.
1993: Mosaic – first graphical web browser for the general public
The first widely downloaded Internet browser, Mosaic, was released in 1993. While Mosaic wasn’t the first web browser, it is considered the first browser to make the Internet easily accessible to non-techies.
1993: Governments join in on the fun
In 1993, both the White House and the United Nations came online, marking the beginning of the .gov and .org domain names.
1994: Netscape Navigator
Mosaic’s first big competitor, Netscape Navigator, was released the year following (1994).
1995: Commercialization of the internet
1995 is often considered the first year the web became commercialized. While there were commercial enterprises online prior to ’95, there were a few key developments that happened that year. First, SSL (Secure Sockets Layer) encryption was developed by Netscape, making it safer to conduct financial transactions (like credit card payments) online.
In addition, two major online businesses got their start the same year. The first sale on “Echo Bay” was made that year. Echo Bay later became eBay. Amazon.com also started in 1995, though it didn’t turn a profit for six years, until 2001.
1995: Geocities, the Vatican goes online, and JavaScript
Other major developments that year included the launch of Geocities (which officially closed down on October 26, 2009).
Java and JavaScript (originally called LiveScript by its creator, Brendan Eich, and deployed as part of the Netscape Navigator browser – see comments for explanation) was first introduced to the public in 1995. ActiveX was launched by Microsoft the following year.
1996: First web-based (webmail) service
In 1996, HoTMaiL (the capitalized letters are an homage to HTML), the first webmail service, was launched.
1997: The term “weblog” is coined
While the first blogs had been around for a few years in one form or another, 1997 was the first year the term “weblog” was used.
1998: First new story to be broken online instead of traditional media
In 1998, the first major news story to be broken online was the Bill Clinton/Monica Lewinsky scandal (also referred to as “Monicagate” among other nicknames), which was posted on The Drudge Reportafter Newsweek killed the story.
1998: Google!
Google went live in 1998, revolutionizing the way in which people find information online.
1998: Internet-based file-sharing gets its roots
In 1998 as well, Napster launched, opening up the gates to mainstream file-sharing of audio files over the internet.
1999: SETI@home project
1999 is the year when one of the more interesting projects ever brought online: the SETI@home project, launched. The project has created the equivalent of a giant supercomputer by harnessing the computing power of more than 3 million computers worldwide, using their processors whenever the screensaver comes on, indicating that the computer is idle. The program analyzes radio telescope data to look for signs of extraterrestrial intelligence.
2000: The bubble bursts
2000 was the year of the dotcom collapse, resulting in huge losses for legions of investors. Hundreds of companies closed, some of which had never turned a profit for their investors. The NASDAQ, which listed a large number of tech companies affected by the bubble, peaked at over 5,000, then lost 10% of its value in a single day, and finally hit bottom in October of 2002.
2001: Wikipedia is launched
With the dotcom collapse still going strong, Wikipedia launched in 2001, one of the websites that paved the way for collective web content generation/social media.
2003: VoIP goes mainstream
In 2003: Skype is released to the public, giving a user-friendly interface to Voice over IP calling.
2003: MySpace becomes the most popular social network
Also in 2003, MySpace opens up its doors. It later grew to be the most popular social network at one time (though it has since been overtaken by Facebook).
2003: CAN-SPAM Act puts a lid on unsolicited emails
Another major advance in 2003 was the signing of the Controlling the Assault of Non-Solicited Pornography and Marketing Act of 2003, better known as the CAN-SPAM Act.
2004: Web 2.0
Though coined in 1999 by Darcy DiNucci, the term “Web 2.0”, referring to websites and Rich Internet Applications (RIA) that are highly interactive and user-driven became popular around 2004. During the first Web 2.0 conference, John Batelle and Tim O’Reilly described the concept of “the Web as a Platform“: software applications built to take advantage of internet connectivity, moving away from the desktop (which has downsides such as operating system dependency and lack of interoperability).
2004: Social Media and Digg
The term “social media”, believed to be first used by Chris Sharpley, was coined in the same year that “Web 2.0” became a mainstream concept. Social media–sites and web applications that allow its users to create and share content and to connect with one another–started around this period. People loved the idea of being able to travel through their friends and families pictures and adventures, despite not being physically present.
Digg, a social news site, launched on November of 2004, paving the way for sites such as Reddit, Mixx, and Yahoo! Buzz. Digg revolutionized traditional means of generating and finding web content, democratically promoting news and web links that are reviewed and voted on by a community.
2004: “The” Facebook open to college students
Facebook launched in 2004, though at the time it was only open to college students and was called “The Facebook”; later on, “The” was dropped from the name, though the URL http://www.thefacebook.com still works.
2005: YouTube – streaming video for the masses
YouTube launched in 2005, bringing free online video hosting and sharing to the masses.
2006: Twitter gets twittering
Twitter launched in 2006. It was originally going to be called twittr (inspired by Flickr); the first Twitter message was “just setting up my twttr”.
2007: Major move to place TV shows online
Hulu was first launched in 2007, a joint venture between ABC, NBC, and Fox to make popular TV shows available to watch online.
2007: The iPhone and the Mobile Web
The biggest innovation of 2007 was almost certainly the iPhone, which was almost wholly responsible for renewed interest in mobile web applications and design.
2008: “Internet Election”
The first “Internet election” took place in 2008 with the U.S. Presidential election. It was the first year that national candidates took full advantage of all the Internet had to offer. Hillary Clinton jumped on board early with YouTube campaign videos. Virtually every candidate had a Facebook page or a Twitter feed, or both.
Ron Paul set a new fundraising record by raising $4.3 million in a single day through online donations, and then beat his own record only weeks later by raising $4.4 million in a single day.
The 2008 elections placed the Internet squarely at the forefront of politics and campaigning, a trend that is unlikely to change any time in the near future.
2009: ICANN policy changes
2009 brought about one of the biggest changes to come to the Internet in a long time when the U.S. relaxed its control over ICANN, the official naming body of the Internet (they’re the organization in charge of registering domain names).
The Future?
Where is the future of the Internet headed? We can only assume that the Internet will continue to grow. From basic developments to things like PPC advertising, the Internet has only become more impressive over time. Share your opinions in the comments section.
Sources and Further Reading
A People’s History of the Internet: from Arpanet in 1969 to Today: A timeline of the Internet from guardian.co.uk.
History of the Internet: An early timeline of the Internet, from precursors in the 1800s up through 1997.
A Brief History of the Web: A series of videos from Microsoft to celebrate the launch of Internet Explorer 8.
Hobbes’ Internet Timeline – the definitive ARPAnet & Internet History: A very thorough timeline of the Internet, starting in 1957 and going up through 2004, with tons of statistics and source material included.
Internet Timeline: A basic timeline of Internet history from FactMonster.com.
For even more digital marketing advice, sign up for the email that more than 190,000 other marketers trust:
Pagination is one of those little design necessities that often gets overlooked. But for blogs and other content-heavy sites, it provides an important means of navigating between pages. A well-crafted paginated website can encourage users to explore further what you have to offer.
Some designers dare to take pagination to the next level. Here’s a look at some very creative CSS and JavaScript code snippets that you can use for free to improve the pagination on your own website.
You might also like these menu and navigation snippet collections:
Our first example shows how some basic hover effects can vastly improve standard pagination. The ultra-smooth underline that follows your cursor makes for a much more intuitive experience. Plus, the entire menu is very easy to read. This is a simple way to help users.
One of the most frustrating parts of pagination can be how menus handle a large number of pages. This snippet uses jQuery to show adjacent page numbers as you click. It’s a much easier path to follow.
This is an exciting concept. Designed to be both responsive and more accessible, this pagination UI contains multiple ways to navigate – including via a keyboard. The timeline-like bar at the top clearly labels the current page and offers a great overview of everything available.
They say good help is hard to find. But this snippet provides the help of a Yeti (at least, the hand of a Yeti) when clicking through the page numbers. While Yetis may not fit with your motif, this is an example of how we can add an element of fun (and surprise).
On smaller screens, pagination can be terribly difficult to use. Navigation items are often too small and too hard to read. This snippet provides a great alternative for mobile devices. Each item is larger as the navigation stretches vertically. The result is that mobile users can get around without having to squint their eyes or zoom in.
Sometimes, we don’t need to number each item within the pagination. This example is attractively minimal with the use of dots rather than numerals. It’s a good solution for slideshows or navigating multiple panels of content.
Mobile UI works best when it reacts to a user’s touch. Here we have pagination that allows the user to swipe to get to the next or previous item. This little convenience can make all the difference when it comes to usability.
Designers often use infinite scrolling to replace pagination. But this is a neat concept of how they can be combined. The frustration of infinite scroll is that it can be difficult to go back and find that one particular item. This snippet adds new page numbers to the navigation as you continue to scroll down, making returning to the previous page a little easier.
A great web design doesn’t ignore the various elements that make up a page. The pros above show that pagination has more to offer when you put some effort into enhancing it.
So, take some inspiration from these examples and create pagination menus that both look and function better.
Tomas Votruba and I first met a couple of years ago at one of my favorite conferences; the Dutch PHP Conference in Amsterdam (so actually, we're very close to our anniversary, Tomas!). He presented Rector there and it was really inspiring. A year later I was working on a legacy migration problem: our team wanted to migrate from Doctrine ORM to "ORM-less", with handwritten mapping code, etc. I first tried Laminas Code, a code generation tool, but it lacked many features, and also the precision that I needed. Suddenly I recalled Rector, and decided to give it a try. After some experimenting, everything worked and I learned that this tool really is amazingly powerful!
Thank you, Tomas
I asked Tomas if he would like to write a book together, about Rector, combining the perspective of a developer who needs to learn how to use and extend Rector, with the perspective of the creator who has a vision for the project. This turned out to be a very fruitful collaboration. To be extremely honest, in the beginning of the project I was really annoyed by Tomas' contributions. As an example, this guy put all of the value object classes in a namespace called ValueObjects. I had never encountered anything like that. He also added all kinds of PHPStan rules that would throw errors in my face whenever I tried to commit anything. At first I was like: that is not how writing a book works, Tomas. You're treating it as a software project. I want to have freedom. I want to treat it like art.
In the end, I realized we were optimizing for different things. He focused on:
Achieving the simplest possible setup for service container configuration.
Never having to remember any special rule: a failing build should remind you of your mistakes.
Maximum maintainability in the long run. This book needs to be useful not only this year, but during the life span of the project itself.
These are very valuable principles, and from this place I'd like to thank Tomas for leading by example here. I'll never forget this, and will make it part of every future project (books and software projects alike). Thanks to this approach, every code sample is analyzed for issues, automatically formatted, and every code sample can be automatically refactored with Rector. When we need to, we can even upgrade the code base to a new PHP version. In fact, we could even decide to downgrade it!
Rector is better because of this book
While writing I often encountered a weird problem. Sometimes it turned out to be bug in Rector, sometimes an edge case that would be solved by a feature that was already on the roadmap (like migrating Rector to use static reflection). In all cases, Tomas was able to improve Rector, making the learning experience for news users much smoother, and more enjoyable.
You'll be a better developer because of this book
Rector is a fascinating tool, but before you can effectively extend it for your own code transformation needs, you have to learn about some other related topics, like tokenizing, parsing, the Abstract Syntax Tree, node visitors, and so on. This book aims to provide a good introduction to all these topics, making you a better developer anyway, even if you'd never actually use Rector.
Conclusion
In conclusion: buy this book. It's now 100% complete. It'll teach you a lot about PHP as a language, how to improve legacy projects without wasting development time, and even about test-driven development.
imagick 3.5.0RC1
- ImageMagick 7 is still not widely available on systems. So contrary to previous plans, ImageMagick 6 support will continue for now. But users are recommeded to use ImageMagick 7 if possible.
Method names have been changed to not be all lower case. Both method names and parameter information is built from the Imagick*.stub.php files.
Prevent accidental creation of zero dimension images. ImageMagick doesn't prevent creation of zero dimension images, but will give an error when that image is used. I don't think this will affect any correctly program, but if it does, and you need to re-enable zero dimension images, please open an issue at https://phpimagick.com/issues
Various pieces of work have been done to make GOMP not segfault including:
Call omp_pause_resource_all when available during shutdown.
Added the 'imagick.shutdown_sleep_count' (default 10) and 'imagick.set_single_thread' (default On). Both of these exist to mitigate the segaults on shutdown.
Fixes:
Correct version check to make RemoveAlphaChannel and FlattenAlphaChannel be available when using Imagick with ImageMagick version 6.7.8-x
Imagick::morphology now no longer ignores channel parameter
Added:
PHP 8.0 support.
Location check for ImageMagick 7 for NixOS and Brew.
Imagick::houghLineImage(int $width, int $height, float $threshold): bool {}
Imagick::setImagePixelColor(int $x, int $y, ImagickPixel|string $color)
Imagick::setImageMask(Imagick $clip_mask, int $pixelmask_type)
Full fledged arginfo is available under PHP 8 (Remi Collet)
Calling dbase functions with wrong parameter types/values throws TypeExceptions and
ValueExceptions, respectively, instead of raising warnings under PHP 8 (Remi Collet)
Bug Fixes
Fixed #80156 (Incomplete records may be written)
Fixed #80488 (ReflectionParameter->getDefaultValue() throws for dbase_create())
event 3.0.5
Fixed a test not working with PHP 8.1.0alpha1
igbinary 3.2.3
* Fix build for php 8.1 after changes to enum internals.
* Update tests to suppress deprecations in php 8.1 and support run-tests.php changes in php 8.1
* Don't emit a notice when unserialize_callback_func causes igbinary_unserialize to throw https://bugs.php.net/bug.php?id=81118









 after a joke, rather than the original -) proposed by MacKenzie. The modern emoticon was born.
after a joke, rather than the original -) proposed by MacKenzie. The modern emoticon was born.