Over 1,400 attendees from 71 countries gathered at the Philippine International Convention Center in Manila, and nearly 15,000 more joined online, for WordCamp Asia 2025.
It’s the people. It’s the friendships and the stories.
Matt Mullenweg, WordPress Cofounder
The flagship WordPress event started with a dedicated Contributor Day, followed by two days of engaging talks, panels, hands-on workshops, and networking. Notable guests included WordPress Cofounder Matt Mullenweg and Gutenberg Lead Architect Matías Ventura, who were joined by a diverse lineup of speakers and panelists.
Throughout the event, the sponsor hall buzzed with activity as companies from across the WordPress ecosystem showcased their latest products, engaged with attendees, and offered live demos and giveaways. Each day, attendees refueled with diverse food offerings featuring Filipino favorites, turning meals into a prime networking opportunity where new connections were made and ideas were exchanged.
New Ways to Engage
This year’s event introduced several new programs to the schedule:
Solutions Spotlight—a series of dynamic 10-minute lightning talks that gave an inside look at innovative products, cutting-edge strategies, and real-world solutions from top-tier sponsors, all designed to help attendees succeed in the WordPress ecosystem. These fast-paced sessions offered a unique opportunity to discover how leading brands are solving challenges, empowering users, and shaping the future of WordPress.
YouthCamp, a dedicated event for kids and teens ages 8-17, offered a full day of free, hands-on sessions designed to spark creativity and introduce the world of WordPress and open source. Through interactive workshops covering web basics, design, and development, participants gained practical skills while exploring the power of building online.
The new Career and Social Corners enhanced networking, fostered meaningful connections, and created new opportunities for those within the WordPress community. Career Corner was the go-to space for attendees exploring career opportunities, connecting with sponsors, and discovering exciting new roles. Meanwhile, Social Corner offered a relaxed, lounge-style environment where attendees could engage in informal discussions over refreshments.
Contributor Day
WordCamp Asia kicked off with an incredible Contributor Day, bringing together almost 800 contributors, many of them new, to collaborate, share knowledge, and give back to WordPress. With 37 dedicated table leads and 16 experts from the Human Library guiding the way, participants of all experience levels engaged in meaningful discussions, tackled important tasks, and made a lasting impact on the WordPress project.
Key contributions included resolving a critical media bug, advancing vertical text editing in Gutenberg, and refining the editing experience with dozens of issue closures. Performance optimizations and accessibility improvements abounded, joined by seven fresh patterns, and over 44,000 newly translated strings.
New tools and workflows were explored to enhance testing and development. The day also saw meaningful conversations between hosting providers and users, improvements to event organizing processes, and hands-on training.
With innovative ideas, new faces, and significant progress across multiple areas, Contributor Day reinforced the spirit of open source collaboration that drives WordPress forward.
The Future is WordPress
On the first full conference day, attendees gathered to celebrate the power of open source collaboration and innovation. Opening remarks from global and local event leads reflected on the incredible journey of WordCamp Asia, tracing its roots back to the first Southeast Asian WordCamp in Manila in 2008. This full-circle moment underscored how the WordPress community has flourished over the years, driven by shared knowledge and a commitment to an open web. The excitement continued with a highly anticipated opening keynote from Matías Ventura, who shared insights into the future of Gutenberg and WordPress, inspiring attendees to embrace the next wave of innovation and creativity in content publishing.
The day then began in earnest. Talks highlighted new ways to integrate WordPress with external applications, opening possibilities for more interactive and scalable digital experiences. Simultaneously, content strategists and marketers explored evolving best practices in SEO, learning how to optimize their sites for visibility, engagement, and long-term growth. These sessions emphasized the importance of adaptability in a constantly evolving digital landscape, ensuring that WordPress users stay ahead of industry trends.
Workshops throughout the day provided hands-on learning experiences tailored to a wide range of skill levels. Developers refined their expertise, gaining practical knowledge they could apply to their own projects. Accessibility advocates led discussions on designing for inclusivity, showcasing strategies to make WordPress-powered websites more navigable and user-friendly for people of all abilities.
As the conference continued into the afternoon, conversations expanded to performance optimization and emerging technologies shaping the future of WordPress. A dedicated session explored AI-driven workflows, demonstrating how artificial intelligence can enhance site performance, automate repetitive tasks, and create more personalized user experiences. These discussions showcased the evolving role of WordPress as a versatile platform that extends beyond traditional publishing.
The first day culminated in a thought-provoking keynote panel, WordPress in 2030, where industry leaders explored the future of the platform. The discussion covered the expanding open source community, emerging technologies, and the role of education and mentorship. Panelists shared their perspectives on the opportunities and challenges ahead, encouraging attendees to actively shape the future of WordPress by contributing, innovating, and advocating for an open web.
Returning for the final day of WordCamp Asia 2025, attendees explored a new set of sessions designed to push the boundaries of web development and strategy. Technical discussions on advanced Gutenberg block development highlighted innovative ways to build more dynamic and interactive content experiences, while another session examined performance optimization strategies to enhance site speed, accessibility, and overall user engagement. Content creators and marketers gained valuable insights into audience growth, effective storytelling, and data-driven content strategies to maximize impact.
The final sessions of the conference reinforced WordPress’s adaptability and innovation, equipping attendees with new skills and strategies.
Q&A
As the final day drew to a close, Matt shared historic photos from WordCamp Davao 2008 in the Philippines, and then answered questions from the audience.
Questions covered a variety of topics, incluiding: publishing on the open web, AI, headless WordPress, education, and Matt’s personal motivations. It was clear throughout the Q&A that the future of WordPress is as bright as the island-themed attire at the event’s after-party.
Closing
Thank you to all the hard-working organizers who made this event possible, the speakers who took the stage, the visitors who ventured to Manila, and everyone who tuned in from around the world. Our hope is that every WordCamp attendee leaves with new knowledge, new friends, and new inspiration to build a better web.
Be sure to mark your calendars for other major WordPress events in 2025: WordCamp Europe (Basel, Switzerland) and WordCamp US (Portland, Oregon, USA). Then join us in Mumbai, India for WordCamp Asia 2026!
I'm working on a new site at https://highperformancewebfonts.com/ where I'm doing everything wrong. E.g. using a joke-y client-side-only rendering of articles from .md files (Hello Lizzy.js)
Since there's no static generation, there was no RSS feed. And since someone asked, I decided to add one. But in the spirit of learning-while-doing, I thought I should do the feed generation in Rust—a language I know nothing about.
A tool called Cargo seems like the way to go. Looks like it's a package manager, an NPM of Rust:
$ cargo new russel && cd russel
(The name of my program is "russel", from "rusty", from "rust". Yeah, I'll see myself out.)
3. Add dependencies to Cargo.toml
And Cargo.toml looks like a config file similar in spirit to package.json and similar in syntax to a php.ini. Since I'll need to write an RSS feed, a package called rss would be handy.
[package]
name = "russel"
version = "0.1.0"
edition = "2021"
[dependencies]
rss = "2.0.0"
Running $ cargo build after a dependency update seems necessary.
We must act now to keep the dream alive. Our family made eight $1 million donations to nonprofit groups working to support those most currently in need:
Team Rubicon – Mobilizing veterans to continue their service, leveraging their skills and experience to help Americans prepare, respond, and recover from natural disasters.
Children’s Hunger Fund – Provides resources to local churches in the United States and around the world to meet the needs of impoverished community members.
PEN America – Defends writers against censorship and abuse, supports writers in need of emergency assistance, and amplifies the writing of incarcerated prisoners. (One of my personal favorites; I’ve seen the power of writing transform our world many times.)
The Trevor Project – Working to change hearts, minds, and laws to support the lives of young adults seeking acceptance as fellow Americans.
First Generation Investors –Introduces high school students in low-income areas to the fundamentals of investing, providing them real money to invest, encouraging long-term wealth accumulation and financial literacy among underserved youth.
Global Refuge – Supporting migrants and refugees from around the globe, in partnership with community-based legal and social service providers nationwide, helping rebuild lives in America.
Planned Parenthood – Provides essential healthcare services and resources that help individuals and families lead healthier lives.
I encourage every American to contribute soon, however you can, to organizations you feel are effectively helping those most currently in need here in America.
We must alsowork toward deeper changes that will take decades to achieve. Over the next five years, my family pledges half our remaining wealth towards long term efforts ensuring that all Americans continue to have access to the American Dream.
I never thought my family would be able to do this. My parents are of hardscrabble rural West Virginia and rural North Carolina origins. They barely managed to claw their way to the bottom of the middle class by the time they ended up in Virginia. Unfortunately, due to the demons passed on to them by their parents, my father was an alcoholic and my mother participated in the drinking. She ended up divorcing my father when I was 16 years old. It was only after the divorce that my parents were able to heal themselves, heal their only child, and stop the drinking, which was so destructive to our family. If the divorce hadn’t forced the issue, alcohol would have inevitably destroyed us all.
My parents may not have done everything right, but they both unconditionally loved me. They taught me how to fully, deeply receive love, and the profound joy of reflecting that love upon everyone around you.
I went on to attend public school in Chesterfield County, Virginia. In 1992 I graduated from the University of Virginia, founded by Thomas Jefferson.
During college, I worked at Safeway as a part-time cashier, earning the federal minimum wage, scraping together whatever money I could through government Pell grants, scholarships, and other part-time work to pay my college tuition. Even with lower in-state tuition, it was rocky. Sometimes I could barely manage tuition payments. And that was in 1992, when tuition was only $3,000 per year. It is now $23,000 per year. College tuition at a state school increased by 8 times over the last 30 years. These huge cost increases for healthcare, education, and housing are not compatible with the American Dream.
Programmers all over the world helped make an American Dream happen in 2008 when we built Stack Overflow, a Q&A website for programmers creating a shared Creative Commons knowledge base for the world. We did it democratically, because that’s the American way. We voted to rank questions and answers, and held elections for community moderators using ranked choice voting. We built a digital democracy – of the programmers, by the programmers, for the programmers. It worked.
With the guidance of my co-founder Joel Spolsky, I came to understand that the digital democracy of Stack Overflow was not enough. We must be brave enough to actively, openly share love with each other. That became the foundation for Discourse, a free, open source tool for constructive, empathetic community discussions that are also Creative Commons. We can disagree in those discussions because Discourse empowers communities to set boundaries the community agrees on, providing tools to democratically govern and strongly moderate by enforcing these boundaries. Digital democracy and empathy, for everyone.
In order for digital democracy to work, we need to see each other through our screens.
We often behave online in ways we never would in the real world because we cannot see the person on the other side of the screen. But as our world becomes more digital, we must extend our kindness through that screen.
I’ve always felt Stack Overflow and Discourse are projects for the public good that happen to be corporations. I probably couldn’t have accomplished this in any other country, and I was rewarded handsomely for a combination of hard work and good luck. That’s what the American Dream promises us.
We built it, and people came. I earned millions of dollars. I thought that was the final part of the American Dream. But it wasn’t.
I recently attended a theater performance of The Outsiders at my son’s public high school. All I really knew was the famous “stay gold” line from the 1983 movie adaptation. But as I sat there in the audience among my neighbors, watching the complete story acted out in front of me by these teenagers, I slowly realized what staying gold actually meant: sharing the American Dream.
In the printed program, the director wrote:
This play is a reminder that strength lies not just in overcoming hardships but in staying true to ourselves and lifting up those around us.
We hope you feel the raw emotions, sense the camaraderie, and connect with the enduring themes of resilience, empathy, and unity. Whether you’ve read this story recently, long ago, or not at all, I hope you are able to find inspiration in the strength and passion of youth. Thank you for being part of this journey with us.
I believe deeply in sharing The American Dream. It is the foundation of our country, the second paragraph in our Declaration of Independence, written by the founder of the public university I attended:
We hold these truths to be self-evident, that all men are created equal, that they are endowed by their Creator with certain unalienable Rights, that among these are Life, Liberty and the pursuit of Happiness.
But the American Dream is not always available to every American. Its meaning can be distorted. Jimi Hendrix captured this distortion so eloquently in his rendition of our national anthem.
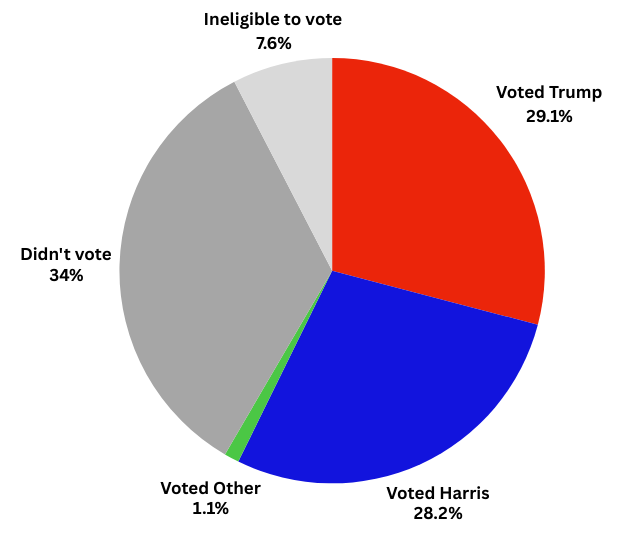
We are still trying to live up to those ideals today. In November 2024, enough of us voted for people who interpret the dream in a way that I don’t understand.
34% of adults in America did not exercise their right to vote. Why? Is it voter suppression, gerrymandering causing indifference, or people who felt their vote didn’t matter? The 7.6% that are ineligible to vote are mostly adults living in America who have not managed to attain citizenship, or people convicted of a felony. Whatever the reasons, 42% of adults living in America had no say in the 2024 election. The vote failed to represent everyone.
I think many of the Americans who did vote are telling us they no longer believe our government is effectively keeping America fair for everyone. Our status as the world’s leading democracy is in question. We should make it easier for more eligible Americans to vote, such as making election day a national holiday, universal mail in voting, and adopting ranked choice voting so all votes carry more weight. We should also strengthen institutions keeping democracy fair for everyone, such as state and local election boards, as well as the Federal Election Commission.
It was only after I attained the dream that I was able to fully see how many Americans have so very little. This much wealth starts to unintentionally distance my family from other Americans. I no longer bother to look at how much items cost, because I don’t have to. We don’t have to think about all these things that are challenging or unreachable for so many others. The more wealth you attain, the more unmistakably clear it becomes how unequal life is for so many of us.
Even with the wealth I have, I can’t imagine what it would feel like to be a billionaire.It is, for lack of a better word, unamerican.
In 2012, the top 1% of Americans held 24% of our country’s wealth. By 2021, the top 1% of Americans held 30%. So many have so little, while a tiny few have massive, wildly disproportionate wealth, which keeps growing. Now the global top 1% hold nearly twice as much wealth as the rest of the world combined.
I grew up poor in America, inspired by the promise of the American Dream that I could better myself and my family by building things that mattered:
Work is service, not gain. The object of work is life, not income. The reward of production is plenty, not private fortune. We should measure the prosperity of a nation not by the number of millionaires, but by the absence of poverty, the prevalence of health, the efficiency of the public schools, and the number of people who can and do read worthwhile books. – Du Bois
Our version of capitalism delivered so much wealth to my family for my hard work in co-founding two successful companies. My partner and I gladly paid our full taxes, and we always planned to give most of our remaining wealth to charities when we pass, following the Warren Buffett Philanthropic Pledge:
More than 99% of my wealth will go to philanthropy during my lifetime or at death.
I admire Buffett, but even having only a tiny fraction of his $325 billion fortune, to me this pledge was incomplete. When would this wealth be transferred?
Last year he amended the pledge, giving all his wealth at death to a charitable trust run by his children, aged 71, 69, and 66, who do not make for natural charitable bedfellows. I am only holding back enough wealth for my children so they can afford college educations and buy a home. I am compelled to, because being a parent is the toughest job I’ve ever had, and I am concerned about their future.
November 5th raised the stakes. It is now time to allocate half the wealth I was so fortunate to be dealt within the next five years, not just for my own family, but for all my fellow Americans.
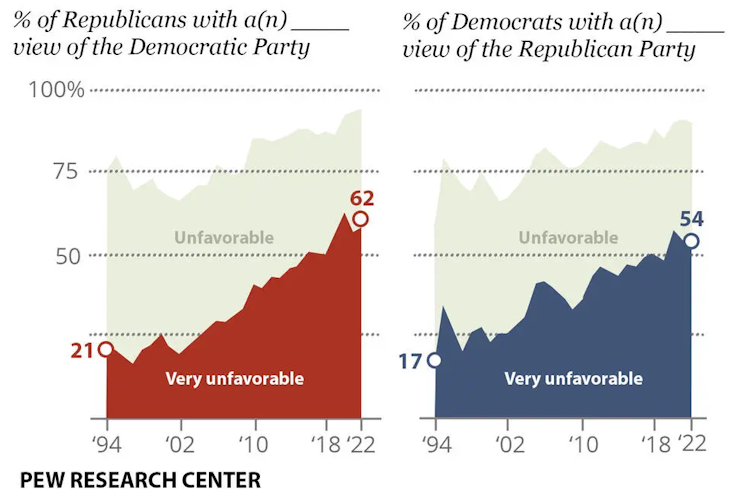
Our government seems to be slower and slower at delivering change due to the increased polarization of our two party system. The last meaningful constitutional amendment we’ve managed to pass in the last 60 years was the 26th amendment in 1971, lowering the voting age to 18 and giving more people a voice in our democracy.
Political polarization is at historically high levels and rising. In a two party system, this level of polarization is counterproductive and even dangerous. Do we all still believe in the same American Dream?
I’ve always loved the ideals behind the American Dream, though we continually struggle to live up to them. They are worth fighting for, even if it means making “good trouble”. We must come together and believe in our shared American Dream so deeply that we can improve our democracy... but which dream?
The American Dream contains the path of hate, and the path of love. Throughout our history, one hand is always fighting the other. Which path are we choosing?
Our family pledges half our remaining wealth toward an American Dream founded on love.
Here are some starting points for longer term efforts:
We can support organizations making it easier for Americans to vote for a new Congress in two years and a new president in four years. My concern is damage to our democratic institutions may happen so quickly that our votes could matter even less within the coming years.
We could fund nonprofits that have a proven track record of protecting democratic institutions.
We could found a new organization loosely based on the original RAND Corporation, but modernized like Lever for Change. We can empower the best and brightest to determine a realistic, achievable path toward preserving the American Dream for everyone, working within the current system or outside it.
All states are shades of purple, not fully red or blue. We have more in common on specific policies than we realize. It would be very difficult to draw borders if we split. I know what divorce feels like, and we don’t want this. Let’s come together through our shared American Dream.
We can start with change in our local communities. Vote in your own city, county, and state elections. Support local independent journalism and media. Find a local organization doing work you admire, ask what they need, and help them meet those needs. Listen to the stories of fellow volunteers, listen to the stories of the people you’re serving – that is the heart of Democracy.
We’ve already completed the eight $1 million donations listed above to help those most immediately in need. Within the next five years, half of our family wealth will support longer term efforts. There is no single solution, so let’s work together. I will gladly advise and empower others working towards the same goal.
Please join us in Sharing the American Dream:
Support organizations you feel are effectively helping those most in need across America right now.
Within the next five years, also contribute public dedications of time or funds towards longer term efforts to keep the American Dream fair and attainable for all our children.
(I could not have done this without the support of my partner Betsy Burton and the rest of my family. I'd also like to thank Steve McConnell, whose writing inspired me to start this blog in 2004. So many people from all walks of life generously shared their feedback to improve this post. We wrote it together. Thank you all.)
When you use a bog-standard WordPress install, the caching header in the HTML response is
Cache-Control: max-age=600
OK, cool, this means cache the HTML for 10 minutes.
Additionally these headers are sent:
Date: Sat, 07 Dec 2024 05:20:02 GMT
Expires: Sat, 07 Dec 2024 05:30:02 GMT
These don't help at all, because they instruct the browser to cache for 10 minutes too, which the browser already knows. These can actually be harmful in cases of clocks that are off. But let's move on.
WP Super Cache
This is a plugin I installed, made by WP folks themselves, so joy, joy, joy. It saves the generated HTML from the PHP code on the disk and then gives that cached content to the next visitor. Win!
However, I noticed it ads another header:
Cache-Control: max-age=3, must-revalidate
And actually now there are two cache-control headers being sent, the new and the old:
What do you think happens? Well, the browser goes with the more restrictive one, so the wonderfully cached (on disk) HTML is now stale after 3 seconds. Not cool!
A settings fix
Looking around in the plugin settings I see there is no way to fix this. There's another curious setting though, disabled by default:
[ ] 304 Browser caching. Improves site performance by checking if the page has changed since the browser last requested it. (Recommended)
304 support is disabled by default because some hosts have had problems with the headers used in the past.
I turned this on. It means that instead of a new request after 3 seconds, the repeat visit will send an If-Modified-Since header, and since 3 seconds is a very short time, the server will very likely respond with 304 Not Modified response, which means the browser is free to use the copy from the browser cache.
Why 600? I'd do it for longer but there's this other Cache-Control 600 coming from who-knows-where, so 600 is the max I can do. (TODO: figure out that other Cache-Control and ditch it)
Why stale-while-revalidate? Well, this lets the browser use the cached response after the 10 minutes while it's re-checking for a fresher copy.
Here you can see no more requests for HTML, just one for stats. No static resources either (CSS, images, JS are cached "forever"). So the page is loaded completely from the browser cache.
Animated gifs are fun and all but they can get big (in filesize) quickly. At some point, maybe after just a few low-resolution frames it's better to use an MP4 and an HTML <video> element. You also preferably need a "poster" image for the video so people can see a quick preview before they decide to play your video. The procedure can be pretty simple thanks to freely available amazing open source command-line tools.
Step 1: an MP4
For this we use ffmpeg:
$ ffmpeg -i amazing.gif amazing.mp4
Step 2: a poster image
Here we use ImageMagick to take the first frame in a gif and export it to a PNG:
$ magick "amazing.gif[0]" amazing.png
... or a JPEG, depending on the type of video (photographic vs more shape-y)
... with your favorite image-smushing tool e.g. ImageOptim
Comments
I did this for a recent Perfplanet calendar post and the 2.5MB gif turned to 270K mp4. Another 23MB gif turned to 1.2MB mp4.
I dunno if my ffmpeg install is to blame but the videos didn't play in QuickTime/FF/Safari, only in Chrome. So I ran them through HandBrake and that solved it. Cuz... ffmpeg options are not for the faint-hearted.
Do use preload="none" so that the browser doesn't load the whole video unless the user decides to play. In my testing without a preload=none Chrome and Safari send range requests (like an HTTP header Range: bytes=0-) for 206 Partial Content. Firefox just gets the whole thing
The Fermi Paradox is a contradiction between high estimates of the probability of the existence of extraterrestrial civilizations, such as in the Drake equation, and lack of any evidence for such civilizations.
There are billions of stars in the galaxy that are similar to the Sun, including many billions of years older than Earth.
With high probability, some of these stars will have Earth-like planets, and if the Earth is typical, some might develop intelligent life.
Some of these civilizations might develop interstellar travel, a step the Earth is investigating now.
Even at the slow pace of currently envisioned interstellar travel, the Milky Way galaxy could be completely traversed in about a million years.
According to this line of thinking, the Earth should have already been visited by extraterrestrial aliens. In an informal conversation, Fermi noted no convincing evidence of this, nor any signs of alien intelligence anywhere in the observable universe, leading him to ask, “Where is everybody?”
Many have argued that the absence of time travelers from the future demonstrates that such technology will never be developed, suggesting that it is impossible. This is analogous to the Fermi paradox related to the absence of evidence of extraterrestrial life. As the absence of extraterrestrial visitors does not categorically prove they do not exist, so the absence of time travelers fails to prove time travel is physically impossible; it might be that time travel is physically possible but is never developed or is cautiously used. Carl Sagan once suggested the possibility that time travelers could be here but are disguising their existence or are not recognized as time travelers.
It seems, to me at least, clear evidence that time travel is not possible, given the enormous amount of time behind us. Something, somewhere, would certainly have invented it by now... right?
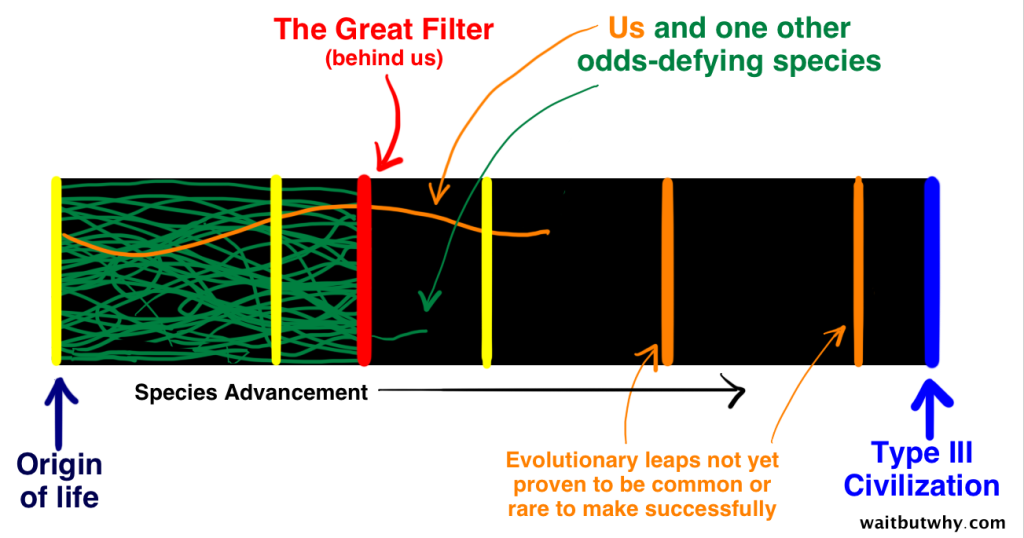
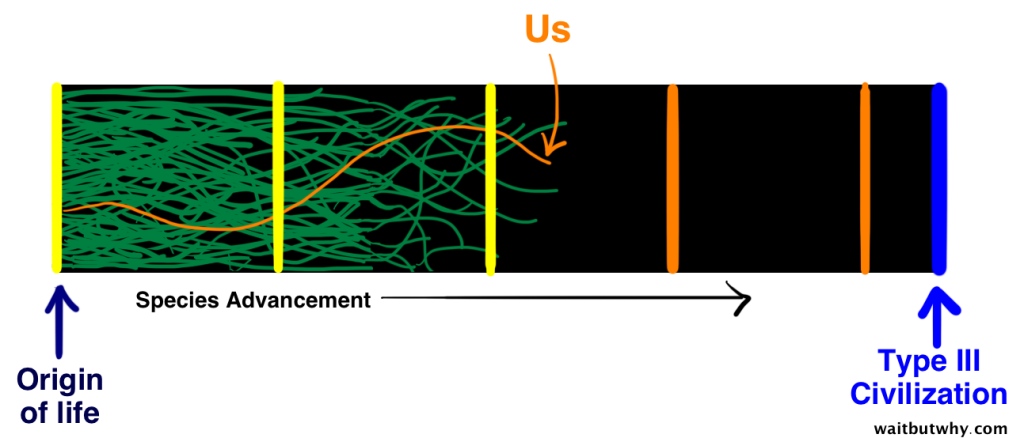
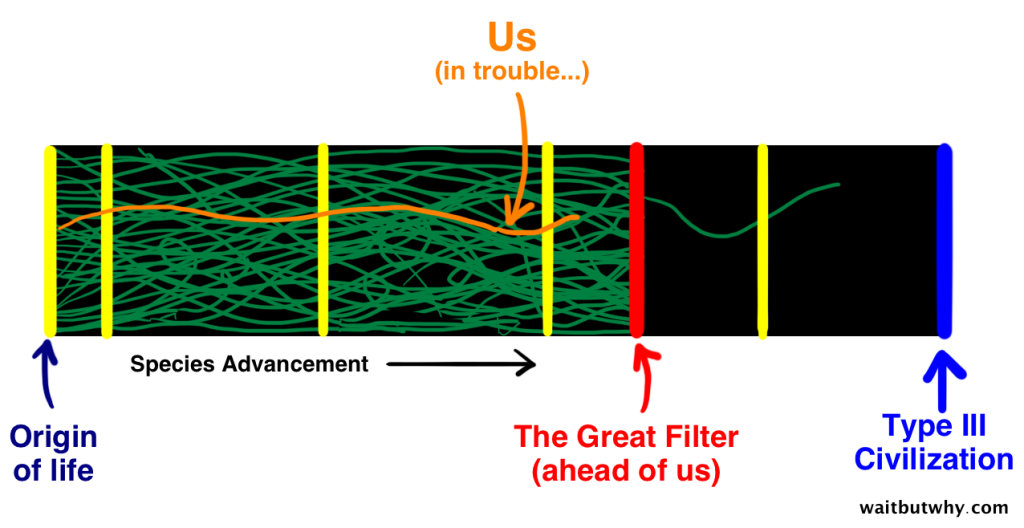
The Great Filter theory says that at some point from pre-life to Type III intelligence, there’s a wall that all or nearly all attempts at life hit. There’s some stage in that long evolutionary process that is extremely unlikely or impossible for life to get beyond. That stage is The Great Filter.
We are not a rare form of life, but near the first to evolve
Almost no life makes it to this point
Those are three Great Filter possibilities, but the question remains: why are we so alone in the observable universe? I grant you that what we can observe is appallingly tiny given the unimaginable scale of the universe, so “what we can observe” may not be enough by many orders of magnitude.
I encourage you to read the entire article, it’s full of great ideas explained well, including many other Great Filter possibilities. Mostly I wanted to share my personal theory of why we haven’t encountered alien life by now. Like computers themselves, things don’t get larger. They get smaller. And faster. And so does intelligent life.
Why build planet-size anything when the real action is in the small things? Small spaces, small units of time, everything gets smaller.
Large is inefficient and unnecessary. Look at the history of computers: from giant to tiny and tinier. From slow to fast and faster. Personally, I have a feeling really advanced life eventually does away with all physical stuff that slows you down as soon as they can, and enters the infinite spaces between:
This is, of course, a variant on the Fermi paradox: We don’t see clues to widespread, large-scale engineering, and consequently we must conclude that we’re alone. But the possibly flawed assumption here is when we say that highly visible construction projects are an inevitable outcome of intelligence. It could be that it’s the engineering of the small, rather than the large, that is inevitable. This follows from the laws of inertia (smaller machines are faster, and require less energy to function) as well as the speed of light (small computers have faster internal communication). It may be – and this is, of course, speculation – that advanced societies are building small technology and have little incentive or need to rearrange the stars in their neighborhoods, for instance. They may prefer to build nanobots instead.
You've seen some of these UIs as of recent AI tools that stream text, right? Like this:
I peeked under the hood of ChatGPT and meta.ai to figure how they work.
Server-sent events
Server-sent events (SSE) seem like the right tool for the job. A server-side script flushes out content whenever it's ready. The browser listens to the content as it's coming down the wire with the help of EventSource() and updates the UI.
(aside:) PHP on the server
Sadly I couldn't make the PHP code work server-side on this here blog, even though I consulted Dreamhost's support. I never got the "chunked" response to flush progressively from the server, I always get the whole response once it's ready. It's not impossible though, it worked for me with a local PHP server (like $ php -S localhost:8000) and I'm pretty sure it used to work on Dreamhost before they switched to FastCGI.
If you want to make flush()-ing work in PHP, here are some pointers to try in .htaccess
Additionally, you can listen to any events with names you decide. For example I want the server to signal to the client that the response is over. So I have the server send this message:
event: imouttahere
data:
And then the client can listen to the imouttahere event:
evtSource.addEventListener('imouttahere', () => {
console.info('Server calls it done');
evtSource.close();
});
Demo time
OK, demo time! The server side script takes a paragraph of text and spits out every word after a random delay:
$txt = "The zebra jumps quickly over a fence, vexed by...";
$words = explode(" ", $txt);
foreach ($words as $word) {
echo "data: $word \n\n";
usleep(rand(90000, 200000)); // Random delay
flush();
}
The client side sets up EventSource and, on every message, updates the text on the page. When the server is done (event: imouttahere), the client closes the connection.
One cool Chrome devtools feature is the list of events under an EventStream tab in the Network panel:
Now, what happens if the server is done and doesn't send a special message (such as imouttahere)? Well, the browser thinks something went wrong and re-requests the same URL and the whole thing repeats. This is probably desired behavior in many cases, but here I don't want it.
The re-request will look like the following... note the error and the repeat request:
Alrighty, that just about clarifies SSE (Server-Sent Events) and provides a small demo to get you started.
In fact, this is the type of "streaming" ChatGPT uses when giving answers, take a look:
In the EventStream tab you can see the messages passing through. The server sends stuff like:
event: delta
data: {json: here}
This should look familiar now, except the chosen event name is "delta" (not the default, optional "message") and the data is JSON-encoded.
And at the end, the server switches back to "message" and the data is "[DONE]" as a way to signal to the client that the answer is complete and the UI can be updated appropriately, e.g. make the STOP button back to SEND (arrow pointing up)
OK, cool story ChatGPT, let's take a gander at what the competition is doing over at meta.ai
XMLHttpRequest
Asking meta.ai a question I don't see EventStream tab, so must be something else. Looking at the Performance panel for UI updates I see:
All of these pinkish, purplish vertical almost-lines are updates. Zooming in on one:
Here we can see XHR readyState change. Aha! Our old friend XMLHttpRequest, the source of all things Ajax!
Looks like with similar server-side flushes meta.ai is streaming the answer. On every readyState change, the client can inspect the current state of the response and grab data from it.
Second, message format. SSE requires a (however simple) format of "event:" and "data:" where data can be JSON-encoded or however you wish. Maybe even XML if you're feeling cheeky. XHR responses are completely free for all, no formatting imposed, and even XML is not required despite the unfortunate name.
And lastly, and most importantly IMO, is that SSE can be interrupted by the client. In my examples I have a "close" button:
document.querySelector('#close').onclick = function () {
console.log('Connection closed');
evtSource.close();
};
Here close() tells the server that's enough and the server takes a breath. No such thing is possible in XHR. And you can see inspecting meta.ai that even though the user can click "stop generating", the response is sent by the server until it completes.
Node.js on the server
Finally, here's my Node.js that I used for the demos. Since I couldn't get Dreamhost to flush() in PHP, I went to Glitch as a free Node hosting to host just this one script.
The code handles requests / for SSE and /xhr for XHR. And there are a few ifs based on XHR vs SSE:
const http = require("http");
const server = http.createServer((req, res) => {
if (req.url === "/" || req.url === "/xhr") {
const xhr = req.url === "/xhr";
res.writeHead(200, {
"Content-Type": xhr ? "text/plain" : "text/event-stream",
"Cache-Control": "no-cache",
"Access-Control-Allow-Origin": "*",
});
if (xhr) {
res.write(" ".repeat(1024)); // for Chrome
}
res.write("\n\n");
const txt = "The zebra jumps quickly over a fence, vexed ...";
const words = txt.split(" ");
let to = 0;
for (let word of words) {
to += Math.floor(Math.random() * 200) + 80;
setTimeout(() => {
if (!xhr) {
res.write(`data: ${word} \n\n`);
} else {
res.write(`${word} `);
}
}, to);
}
if (!xhr) {
setTimeout(() => {
res.write("event: imouttahere\n");
res.write("data:\n\n");
res.end();
}, to + 1000);
}
req.on("close", () => {
res.end();
});
} else {
res.writeHead(404);
res.end("Not Found\n");
}
});
const port = 8080;
server.listen(port, () => {
console.log(`Server started on port ${port}`);
});
Note the weird-looking line:
res.write(" ".repeat(1024)); // for Chrome
In the world of flushing, there are many foes that want to buffer the output. Apache, PHP, mod_gzip, you name it. Even the browser. Sometimes it's required to flush out some emptiness (in this case 1K of spaces). I was actually pleasantly surprised that not too much of it was needed. In my testing this 1K buffer was needed only in the XHR case and only in Chrome.
That's all folks!
If you want to inspect the endpoints here they are:
Web Sockets are yet another alternative to streaming content. Probably the most complex of the three in terms of implementation. Perplexity.ai and MS Copilot seem to have went this route:
While at the most recent performance.now() conference, I had a little chat with Andy Davies about fonts and he mentioned it'd be cool if, while subsetting, you can easily create a second subset file that contains all the "rejects". All the characters that were not included in the initially desired subset.
And as the flight from Amsterdam is pretty long, I hacked on just that. Say hello to a new script, available as an NPM package, called...
Initially I was thinking to wrap around Glyphhanger and do both subsets, but decided that there's no point in wrapping Glyphhanger to do what Glyphhanger already does. So the initial subset is left to the user to do in any way they see fit. What I set out to do was take The Source (the complete font file) and The Subset and produce an inversion, where
The Inverted Subset = The Source - The Subset
This way if your subset is all Latin characters, the inversion will be all non-Latin characters.
When you craft the @font-face declaration, you can use the Unicode range of the subset, like
Then for the occasional character that is not in this range, you can let the browser load the inverted subset. But that should be rare, otherwise an oft-needed character will be in the original subset.
Save on HTTP requests and bytes (in 99% of cases) and yet, take care of all characters your font supports for that extra special 1% of cases.
Unicode-optional
Wakamaifondue can generate the Unicode range for the inverted subset too but it's not required (it's too long!) only if the inverted declaration comes first. In other words if you have:
... and only Latin characters on the page, then Oxanium-inverse-subset.woff2 is NOT going to be downloaded, because the second declaration overwrites the first.
If you flip the two @font-face blocks, the inversion will be loaded because it claims to support everything. And the Latin will be loaded too, because the inversion proves inadequate.
If you cannot guarantee the order of @font-faces for some reason, specifying a scary-looking Unicode range for the inversion is advisable:
This is part 4 of an ongoing study of web font file sizes, subsetting, and file sizes of the subsets.
I used the collection of freely available web fonts that is Google Fonts.
In part 1 I wondered How many bytes is "normal" for a web font by studying all regular fonts, meaning no bolds, italics, etc. The answer was, of course 42, around 20K for a LATIN subset
In part 2 I wondered how does a font grow, by subsetting fonts one character at a time. The answer was, of course 42, about 0.1K per character
Part 3 was a re-study of part 1, but this time focusing on variable fonts using only one variable dimension - weight, i.e. a variable bold-ness. This time the answer was, of course 42,: 35K is the median file size of a wght-variable font
Now, instead of focusing on just regular or just weight-variable fonts, I thought let's just do them all and let you, my dear reader, do your own filtering, analysis and conclusions.
One constraint I kept was just focusing on the LATIN subset (see part 1 as to what LATIN means) because as Boris Shapira notes: "...even with basic high school Chinese, we would need a minimum of 3,000 characters..." which is order of magnitude larger than Latin and we do need to keep some sort of apples-to-apples here.
Then subset all of them fonts to LATIN and drop all fonts that don't support at least 200 characters. 200 and a bit is what the average LATIN font out there supports. This resulted in excluding fonts that focus mostly on non-Latin, e.g. Chinese characters. But it also dropped some fonts that are close to 200 Latin characters but not quite there. See part 1 for the "magic" 200 number. So this replicates part 1 and part 3 but this time for all available fonts.
This 200-LATIN filtering leaves us with 3277 font files to study and 261 font file "rejects". The full list of rejects is rejects.txt
Finally, subset each of the remaining fonts, 10 characters at a time to see how they grow. This replicates part 2 for all fonts, albeit a bit more coarse (10 characters at a time as opposed to 1. Hey, it still took over 24 hours while running 10 threads simultaneously, meaning 10 copies of the subsetting script!). The subsets are 1 character, 10, characters, 20... up to 200. I ended up with 68,817 font files.